
Analyse de données Twitter avec R: Exploration du contenu des tweets
Partie 3: Exploration du contenu des tweets
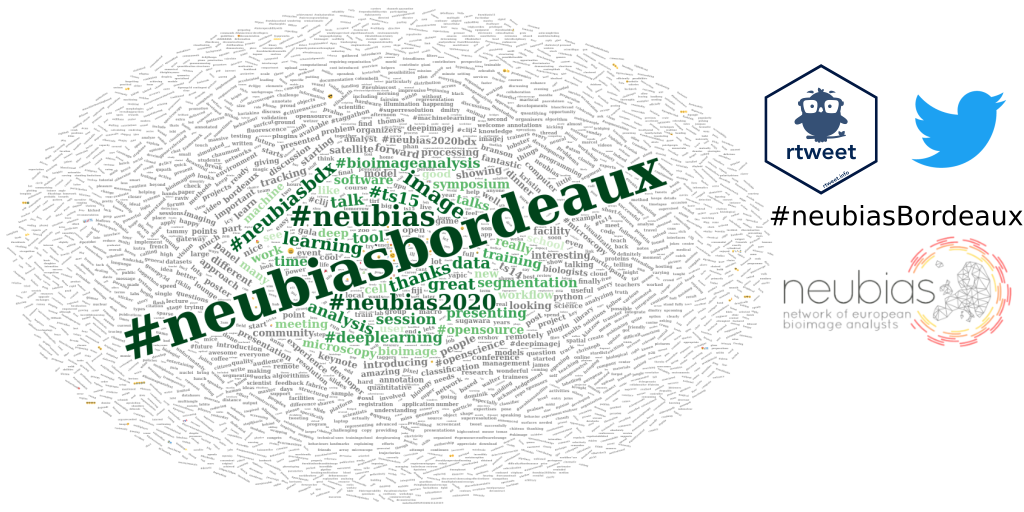
Dans cet article de blog, j’utilise le package R {rtweet} pour explorer les profils et relations des utilisateurs Twitter dont j’ai collecté les statuts lors d’une conférence scientifique. Il s’agit de la troisième et dernière partie de ma série d’articles sur le thème “Analyse de données Twitter avec R”. Dans la première partie, j’ai montré comment j’ai comment j’ai collecté les statuts relatifs à une conférence scientifique. Dans la deuxième partie, j’ai exploré les profils des utilisateurs Twitter présents dans le jeu de données et leur relations.
Twitter est l’un des rares médias sociaux utilisés dans la communauté scientifique. Les utilisateurs ayant un profil scientifique sur Twitter communiquent sur la publication récente d’articles de recherche, les outils qu’ils utilisent, par exemple des logiciels ou des microscopes, les séminaires et conférences auxquels ils assistent ou leur vie de scientifique. Par exemple, sur mon compte Twitter personnel, je partage mes articles de blog, mes documents de recherche et mes diapositives, et je retweete (= je partage) ou je like (= j’aime) les sujets en lien avec la programmation avec R ou l’analyse d’images biologiques.
Twitter archive tous les tweets et offre une API pour effectuer des recherches sur ces données. Le package {rtweet} fournit une interface entre l’API de Twitter et R.
J’ai recueilli des données lors de la conférence 2020 NEUBIAS qui s’est tenue un peu plus tôt cette année à Bordeaux. NEUBIAS, pour “Network of EUropean BioImage AnalystS”, est un réseau scientifique créé en 2016 et soutenu jusqu’à cette année par les fonds européens COST. Les bioimage analysts extraient et visualisent des données provenant d’images biologiques (principalement des images de microscopie mais pas exclusivement) en utilisant des algorithmes et des logiciels d’analyse d’images développés par des laboratoires de recherche en analyse d’image pour répondre à des questions biologiques, soit pour leurs propres recherches en biologie, soit pour d’autres scientifiques. Je me considère comme une bioimage analyst, et je suis une membre active de NEUBIAS depuis 2017. J’ai notamment contribué à la création d’un réseau local de bioimage analysts lors de mon post-doctorat à Heidelberg de 2016 à 2019 et à la co-organisation de deux écoles thématiques NEUBIAS. J’ai également donné des cours et TD lors de trois écoles thématiques NEUBIAS. De plus, j’ai récemment co-créé un bot Twitter appelé Talk_BioImg, qui retweete le hashtag #BioimageAnalysis, afin d’encourager les gens de cette communauté à se connecter les uns aux autres sur Twitter (voir “Announcing the creation of a Twitter bot retweeting #BioimageAnalysis” and “Create a Twitter bot on a raspberry Pi 3 using R”, en anglais, pour plus d’informations).
Dans la première partie de cette série d’articles de blog intitulée “Analyse de données Twitter avec R: Collecte des statuts Twitter liés à une conférence scientifique”, j’ai expliqué comment j’ai récupéré les statuts Twitter contenant au moins un des hashtags de la conférence NEUBIAS. Dans la deuxième partie, j’ai exploré les profils des utilisateurs Twitter présents dans le jeu de données et leur relations.
Dans cette troisième et dernière partie, j’explore le contenu des tweets :
- hashtags de la conférence les plus populaires
- hashtags associés aux hashtags de la conférence
- émojis utilisés le plus fréquemment
- nuage de mots
Packages
Pour stocker et lire les données au format RDS, j’utilise le package {readr}. Pour manipuler et nettoyer les données, j’utilise {dplyr}, {forcats}, {purrr} et {tidyr}. Pour visualiser les données collectées, j’utilise {ggplot2} et {RColorBrewer}. Pour extraire les émojis à partir des tweets, j’utilise la base de données d’émojis de {rtweet}. Pour construire le corpus à partir des textes des tweets, j’utilise le package {tm} et pour afficher le nuage de mots j’utilise {wordcloud2}.
library(dplyr)
library(forcats)
library(ggplot2)
library(here)
library(purrr)
library(readr)
library(RColorBrewer)
library(rtweet)
library(stringr)
library(tidyr)
library(tm)
library(wordcloud2)Graphiques: Thème et palette
Le code ci-dessous définit un thème et une palette de couleurs communs à toutes les graphiques. La fonction theme_set() de {ggplot2} définit le thème pour tous les graphiques.
# Define a personnal theme
custom_plot_theme <- function(...){
theme_classic() %+replace%
theme(panel.grid = element_blank(),
axis.line = element_line(size = .7, color = "black"),
axis.text = element_text(size = 11),
axis.title = element_text(size = 12),
legend.text = element_text(size = 11),
legend.title = element_text(size = 12),
legend.key.size = unit(0.4, "cm"),
strip.text.x = element_text(size = 12, colour = "black", angle = 0),
strip.text.y = element_text(size = 12, colour = "black", angle = 90))
}
## Set theme for all plots
theme_set(custom_plot_theme())
# Define a palette for graphs
greenpal <- colorRampPalette(brewer.pal(9,"Greens"))Lecture des données collectées dans la partie 1
Les données originales peuvent être téléchargées ici. Voir la partie 1 “Analyse de données Twitter avec R: Collecte des statuts Twitter liés à une conférence scientifique” pour plus d’informations sur comment j’ai collecté et aggrégé ces statuts Twitter.
Identification du hashtag de la conférence le plus populaire
Comme je l’ai mentionné dans la partie 1 “Analyse de données Twitter avec R: Collecte des statuts Twitter liés à une conférence scientifique”, les organisateurs locaux ont défini plusieurs hashtags pour la conférence NEUBIAS que j’ai appelé les “hashtags de la conférence”. Comme l’illustre le fil Twitter ci-dessous, cela a soulevé deux grandes questions : pourquoi plusieurs hashtags au lieu d’un seul ? lequel sera le plus populaire ?
tweet_shot("https://twitter.com/VincentMaioli/status/1233458216413126657")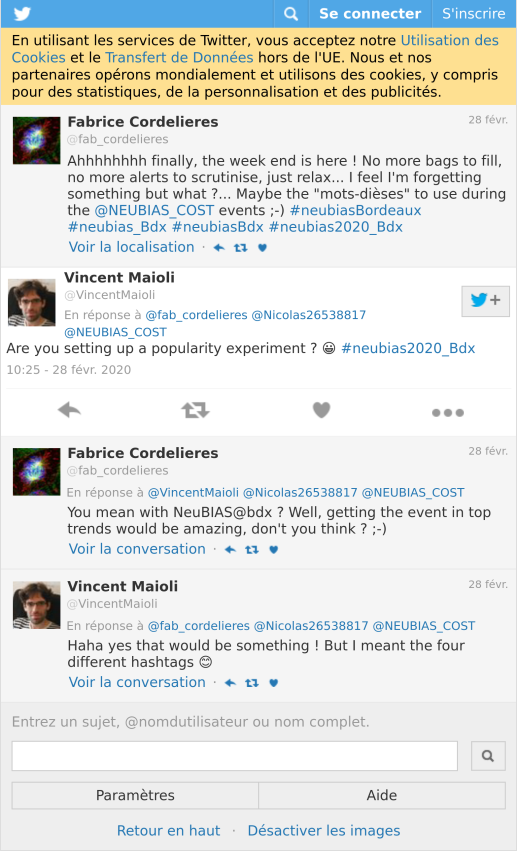
Dans les données que j’ai collectées et aggrégées dans la partie 1 “Analyse de données Twitter avec R: Collecte des statuts Twitter liés à une conférence scientifique”, la colonne hashtags regroupe au format liste les hashtags utilisés pour chaque statut Twitter (tweet ou retweet).
all_neubiasBdx_unique %>%
filter(!is_retweet) %>%
select(hashtags) %>%
as.data.frame() %>%
head() %>%
knitr::kable()| hashtags |
|---|
| c(“bioimageanalysis”, “neubiasBordeaux”) |
| c(“clij”, “clij2”, “neubiasBordeaux”, “opensource”, “GPUpower”) |
| neubiasBordeaux |
| neubiasBordeaux |
| neubiasBordeaux |
| c(“neubiasBordeaux”, “openscience”, “bioimageanalysis”) |
Ici, je choisis de travailler uniquement sur les tweets et non sur les retweets pour mettre en valeur les choix des utilisateurs de Twitter, et non ce qui a été amplifié au final. J’aplatis les listes de la colonne “hashtags” en lignes séparées à l’aide de la fonction unnest(). Ensuite, je ne garde que les hashtags de la conférence. Et je les compte et les classe par ordre décroissant.
most_popular <- all_neubiasBdx_unique %>%
filter(!is_retweet) %>%
unnest(hashtags) %>%
mutate(hashtags_unnest = tolower(hashtags)) %>%
filter(!is.na(hashtags_unnest)) %>%
filter(hashtags_unnest %in% c("neubiasbordeaux", "neubias_bdx", "neubiasbdx",
"neubias2020_bdx", "neubias2020")) %>%
count(hashtags_unnest) %>%
arrange(desc(n)) %>%
top_n(10, n)Le hashtag de la conférence le plus populaire est clairement #neubiasbordeaux. Il a été utilisé dans 561 tweets sur un total de 661 tweets, ce qui signifie qu’environ 85% des tweets dans ce jeu de données contiennent ce hashtag.
ggplot(data = most_popular) +
geom_col(aes(fct_reorder(hashtags_unnest, n), n, fill = n),
colour = "grey30", width = 1) +
labs(x = "", y = "", title = "Conference hashtags") +
coord_flip() +
scale_fill_gradientn("n", colours = greenpal(10), guide = "none") +
scale_y_continuous(expand = c(0, 0)) +
scale_x_discrete(expand = c(0, 0)) 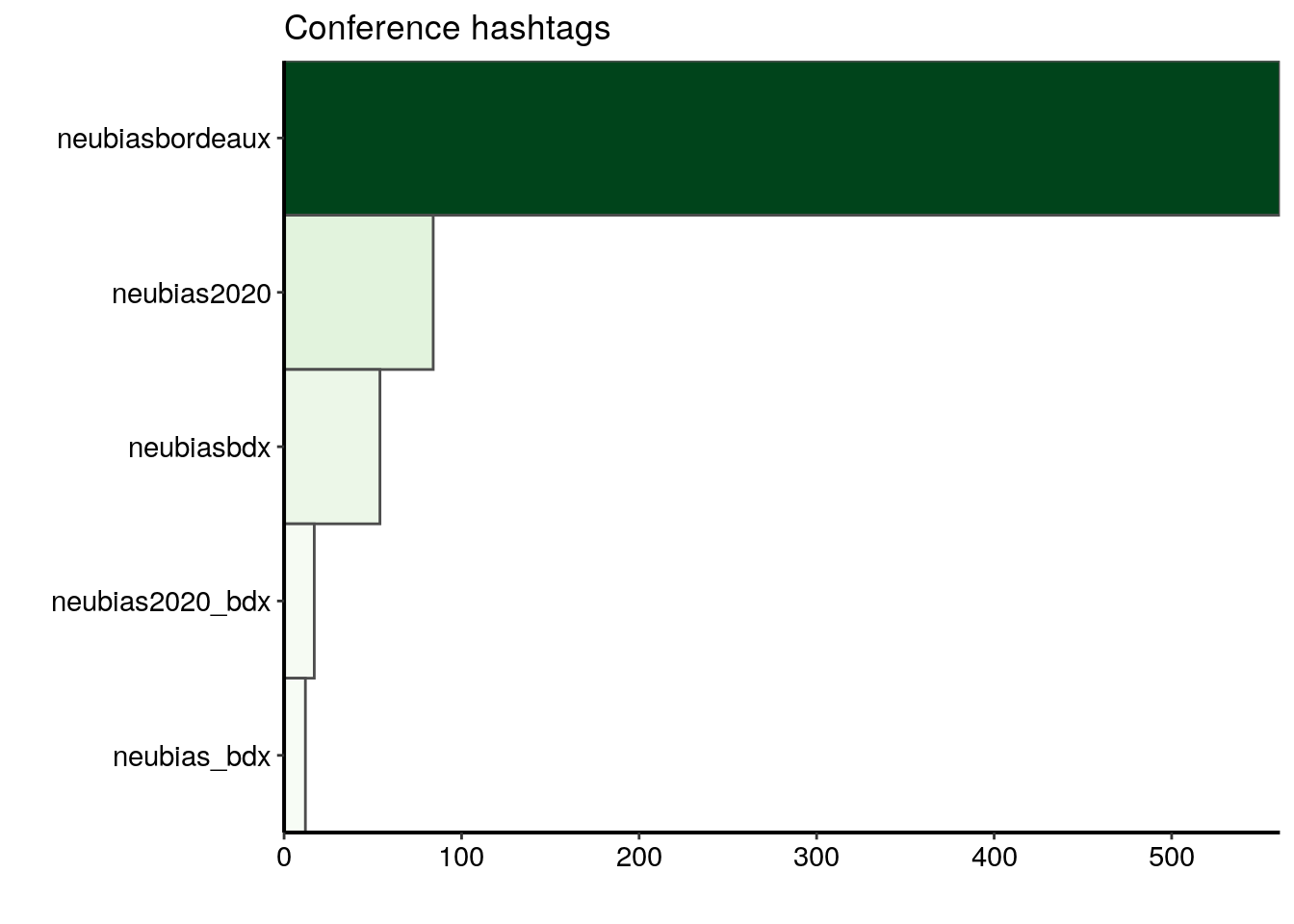
Extraction des hashtags associés aux hashtags de la conférence
A nouveau, je choisis de travailler uniquement sur les tweets et non sur les retweets pour mettre en valeur les choix des utilisateurs de Twitter, et non ce qui a été amplifié au final. Comme ci-dessus, j’aplatis les listes de la colonne hashtags en lignes séparées à l’aide de la fonction unnest()
Cette fois-ci, je garde tous les hashtags sauf ceux de la conférence grâce à la fonction '%!in%' que j’ai moi même créé et qui réalise l’opération inverse de %in%. Je compte ensuite les hashtags et je les classe par ordre décroissant.
'%!in%' <- function(x,y)!('%in%'(x,y))
hashtags_count <- all_neubiasBdx_unique %>%
filter(!is_retweet) %>%
unnest(hashtags) %>%
mutate(hashtags_unnest = tolower(hashtags)) %>%
filter(!is.na(hashtags_unnest)) %>%
filter(hashtags_unnest %!in% c("neubiasbordeaux", "neubias_bdx", "neubiasbdx",
"neubias2020_bdx", "neubias2020")) %>%
count(hashtags_unnest) %>%
arrange(desc(n)) %>%
top_n(10, n)Dans le graphique ci-dessous, je mets en avant les dix hashtags les plus fréquemment associés avec les hashtags de la conférence. Je vois trois catégories de hashtags:
1) des mots se rapportant à la conférence: neubias, qui est le nom du réseau organisant la conférence, et ts15, le nom d’une des training schools
2) des mots se rapportant au domaine de la bioimage analyse: bioimageanalysis, deeplearning, opensource, openscience et microscopy
3) des mots se rapportant à un outil de bioimage analyse en particulier: deepimagej, clij and clij2 (trois plugins ImageJ/Fiji)
ggplot(data = hashtags_count) +
geom_col(aes(fct_reorder(hashtags_unnest, n), n, fill = n),
colour = "grey30", width = 1) +
labs(x = "", y = "", title = "Top 10 associated hashtags") +
coord_flip() +
scale_fill_gradientn("n", colours = greenpal(10)) +
scale_y_continuous(expand = c(0, 0)) +
scale_x_discrete(expand = c(0, 0)) +
theme(legend.position = "none")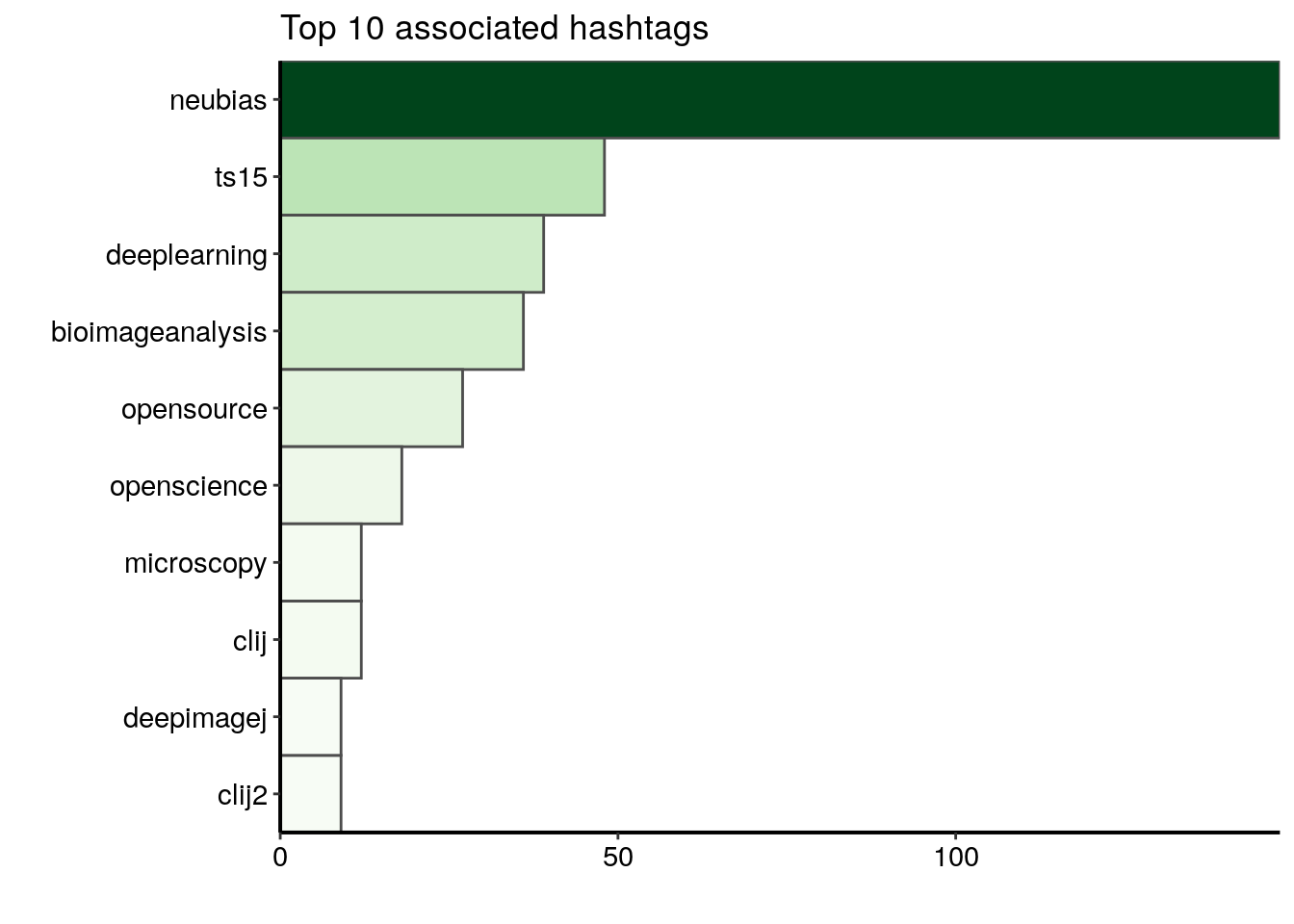
Exploration des émojis et du contenu des tweets
J’aimerais compter le nombre d’émojis et mettre en évidence les mots les plus utilisés dans les tweets à l’aide d’un nuage de mots. Dans les données que j’ai collectées et aggrégées dans la partie 1 “Analyse de données Twitter avec R: Collecte des statuts Twitter liés à une conférence scientifique”, la colonne text contient le texte de chaque tweet. Je ne peux pas utiliser directement le contenu de la colonne de texte car les tweets sont pleins de signes de ponctuation, de chiffres, d’URL, etc.
all_neubiasBdx_unique %>%
filter(!is_retweet) %>%
select(text) %>%
mutate(text = gsub(pattern = "\\n\\n", replacement = "\\n", x = text)) %>%
head() %>%
knitr::kable(escape = TRUE)| text |
|---|
| @BoSoxBioBeth points out to train the trainers. Like a @thecarpentries curriculum for bioimageanalysts #bioimageanalysis #neubiasBordeaux @NEUBIAS_COST |
| Now @haesleinhuepf from @csbdresden @mpicbg with #clij and #clij2 and beautiful time-lapse movies of Tribolium development! #neubiasBordeaux #opensource #GPUpower shout-out to @Jain_Akanksha_ who provided the initial Tribolium cultures! https://t.co/bGKPSCFL2z |
| Approaches @institutpasteur: open-desk sessions save time since questions are answered in large audience. Once a week so not long waiting time. Entry points for projects and collaboration. 25% increasen 2019 @StRigaud #neubiasBordeaux |
| @SimonFlyvbjerg Factoid: “no publications in the first 4 years” @SimonFlyvbjerg ufff that sounds discouraging! #neubiasBordeaux @NEUBIAS_COST nReasons: physical absence, time-lag serice publishing, approach: needs to be brought up at the beginning, written agreement, followup! |
| @florianjug @BoSoxBioBeth @Co_Biologists @neuromusic @ChiguireKun @ilastik_team @NEUBIAS_COST @FijiSc I would not say strange. I think @FijiSc is visible at #neubiasBordeaux. It is also good to have a wide range of representatives at this panel. Maybe @FijiSc needs a bit of a sharper profile also in terms of representation overall. I try to hold the Fiji flag high for my part :) |
| @IgnacioArganda introducing us to machine learning and later deep learning with @FijiSc #neubiasBordeaux #openscience #bioimageanalysis super cool, check it out: https://t.co/Wf1iYzQZqA https://t.co/74yjN4kOeL |
Je dois filtrer les données pour ne garder que les tweets, et non les retweets, puis nettoyer le contenu du texte des tweets, c’est-à-dire supprimer les noms de compte, les urls, les signes de ponctuation et les chiffres, et mettre le texte en minuscules.
text_only <- all_neubiasBdx_unique %>%
filter(!is_retweet) %>%
mutate(
# add spaces before the # and @
clean_text = gsub(x = text, pattern = "(?=@)",
replacement = " ", perl = TRUE) %>%
gsub(x = ., pattern = "(?=#)", replacement = " ", perl = TRUE) %>%
str_replace_all(pattern = "\n", replacement = "") %>%
str_replace_all(pattern = "&", replacement = "") %>%
# remove accounts mentionned with an @
str_replace_all(pattern = "@([[:punct:]]*\\w*)*", replacement = "") %>%
# remove URLs
str_replace_all(pattern = "http([[:punct:]]*\\w*)*", replacement = "") %>%
# remove punctuaction signs except #
gsub(x = ., pattern = "(?!#)[[:punct:]]",
replacement = "", perl = TRUE) %>%
# lowercase the text
tolower() %>%
# remove isolated digits
str_replace_all(pattern = " [[:digit:]]* ", replacement = " ")
)Extraction des émojis contenus dans les tweets
Je regarde maintenant les émojis contenus dans les tweets. J’utilise le jeu de données emojis du package {rtweet} pour identifier les émojis dans le texte des tweets.
all_emojis_in_tweets <- emojis %>%
# for each emoji, find tweets containing this emoji
mutate(tweet = map(code, ~grep(.x, text_only$text))) %>%
unnest(tweet) %>%
# count the number of tweets in which each emoji was found
count(code, description) %>%
mutate(emoji = paste(code, description)) Seulement 71 émojis différents ont été utilisés dans les tweets de ce jeu de donnée et la plupart d’entre eux ne sont pas utilisés plus de deux fois. Dans le top 20 des émojis les plus utilisés, je trouve de nombreux visages souriants et heureux, ainsi que quelques symboles liés au domaine de l’analyse des bioimages, comme un ordinateur portable ou un microscope.
all_emojis_in_tweets %>%
top_n(20, n) %>%
ggplot() +
geom_col(aes(x = fct_reorder(emoji, n), y = n, fill = n),
colour = "grey30", width = 1) +
labs(x = "", y = "Count", title = "Most used emojis") +
coord_flip() +
scale_fill_gradientn("n", colours = greenpal(10), guide = "none") +
scale_y_continuous(expand = c(0, 0),
breaks=seq(0, 10, 2), limits = c(0,10)) +
scale_x_discrete(expand = c(0, 0)) 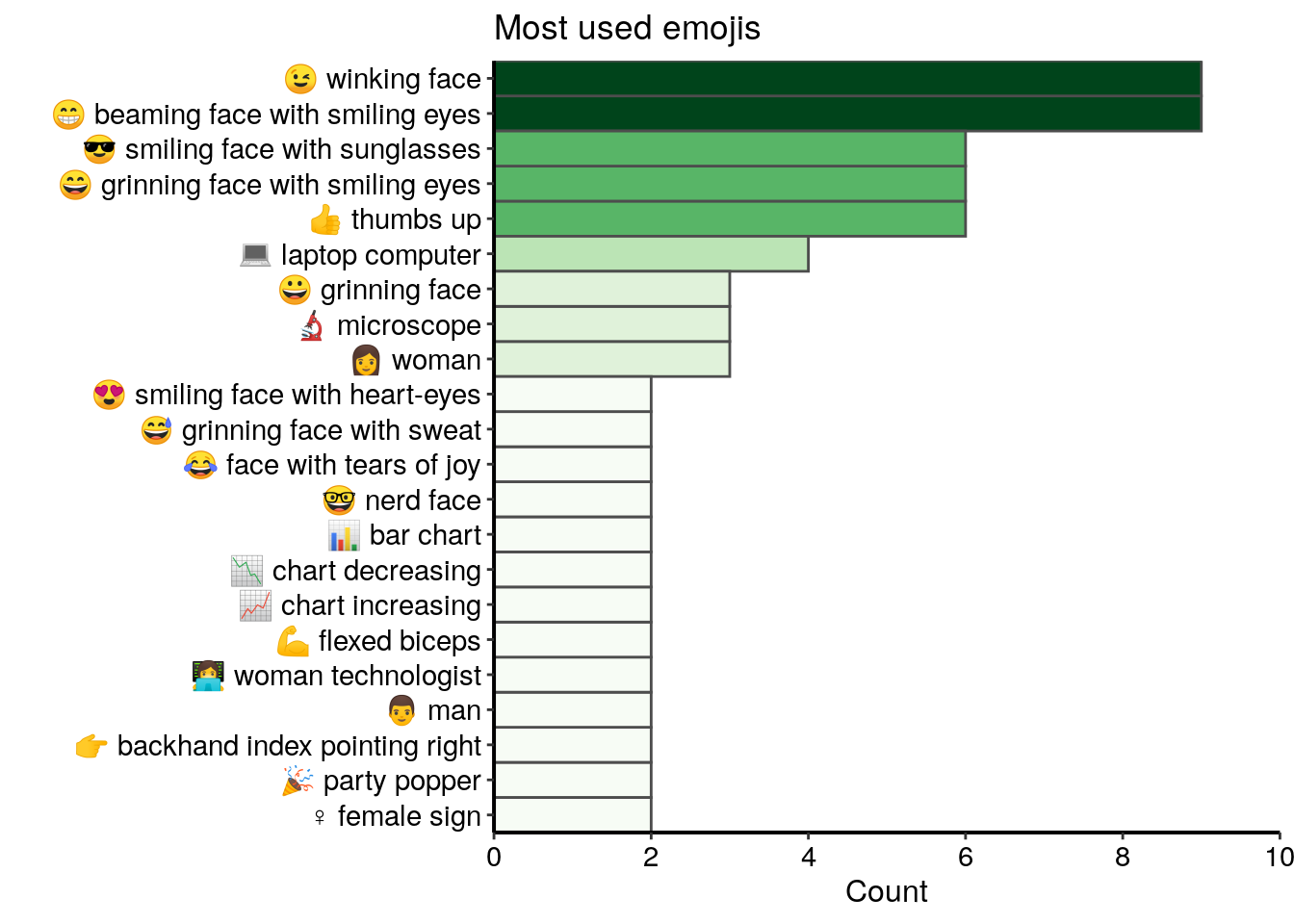
Exploration du contenu textuel des tweets avec un nuage de mots
Je souhaiterais maintenant mettre en évidence les mots les plus utilisés dans les tweets à l’aide d’un nuage de mots. Comme je n’ai pas enlevé le #, je vais pouvoir séparer visuellement les hashtags des autres mots. Pour créer un wordcloud, j’utilise une procédure similaire à celle que j’ai décrite dans l’article Analyse de références bibliographiques avec R. Je convertis tout d’abord le texte nettoyé en un corpus puis je retire les mots de liaisons, les espaces, les pluriels et les mots trop communs.
docs <- SimpleCorpus(VectorSource(text_only$clean_text),
control = list(language = "en"))
docs_cleaned <- tm_map(docs, removeWords, stopwords("english"))
docs_cleaned <- tm_map(docs_cleaned, stripWhitespace)
tosingular <- content_transformer(
function(x, pattern, replacement) gsub(pattern, replacement, x)
)
docs_cleaned <- tm_map(docs_cleaned, tosingular, "cells", "cell")
docs_cleaned <- tm_map(docs_cleaned, tosingular, "workflows", "workflow")
docs_cleaned <- tm_map(docs_cleaned, tosingular, "tools", "tool")
docs_cleaned <- tm_map(docs_cleaned, tosingular, "images", "image")
docs_cleaned <- tm_map(docs_cleaned, tosingular, "users", "user")
docs_cleaned <- tm_map(docs_cleaned, tosingular, "analysts", "analyst")
docs_cleaned <- tm_map(docs_cleaned, tosingular, "developers", "developer")
docs_cleaned <- tm_map(docs_cleaned, tosingular, "schools", "school")
rm_words <- c("will", "use", "used", "using", "today", "can", "one", "join", "day", "week", "just", "come", "first", "last", "get", "next", "via", "dont", "also", "want", "make", "take", "may", "still", "need", "now", "another", "maybe", "getting", "since", "way")
docs_cleaned <- tm_map(docs_cleaned, removeWords, rm_words)Pour visualiser le corpus, j’utilise la fonction inspect() du package {tm}.
inspect(docs_cleaned)Puis je crée la matrice term-document. Pour rappel, la matrice term-document est un tableau de contingence avec tous les mots et le nombre d’occurence de chacun.
dtm <- TermDocumentMatrix(docs_cleaned)
m <- as.matrix(dtm)
v <- sort(rowSums(m), decreasing = TRUE)
d <- data.frame(word = names(v), freq = v)Je visualise d’abord le top 15 des mots à l’exclusion des hashtags de la conférence. Je trouve quelques hashtags autres que ceux de la conférence, des mots liés au lexique de la conférence et les mots positifs “thanks” et “great”.
d %>%
filter(word %!in% c("#neubiasbordeaux", "#neubias_bdx", "#neubiasbdx",
"#neubias2020_bdx", "#neubias2020")) %>%
top_n(15, freq) %>%
ggplot() +
geom_col(aes(fct_reorder(word, freq), freq, fill = freq),
colour = "grey30", width = 1) +
labs(x = "", y = "Count of occurences",
title = "Top 10 words, excluding conference hashtags") +
coord_flip() +
scale_fill_gradientn("freq", colours = greenpal(10), guide = FALSE) +
scale_y_continuous(expand = c(0, 0)) +
scale_x_discrete(expand = c(0, 0)) +
custom_plot_theme()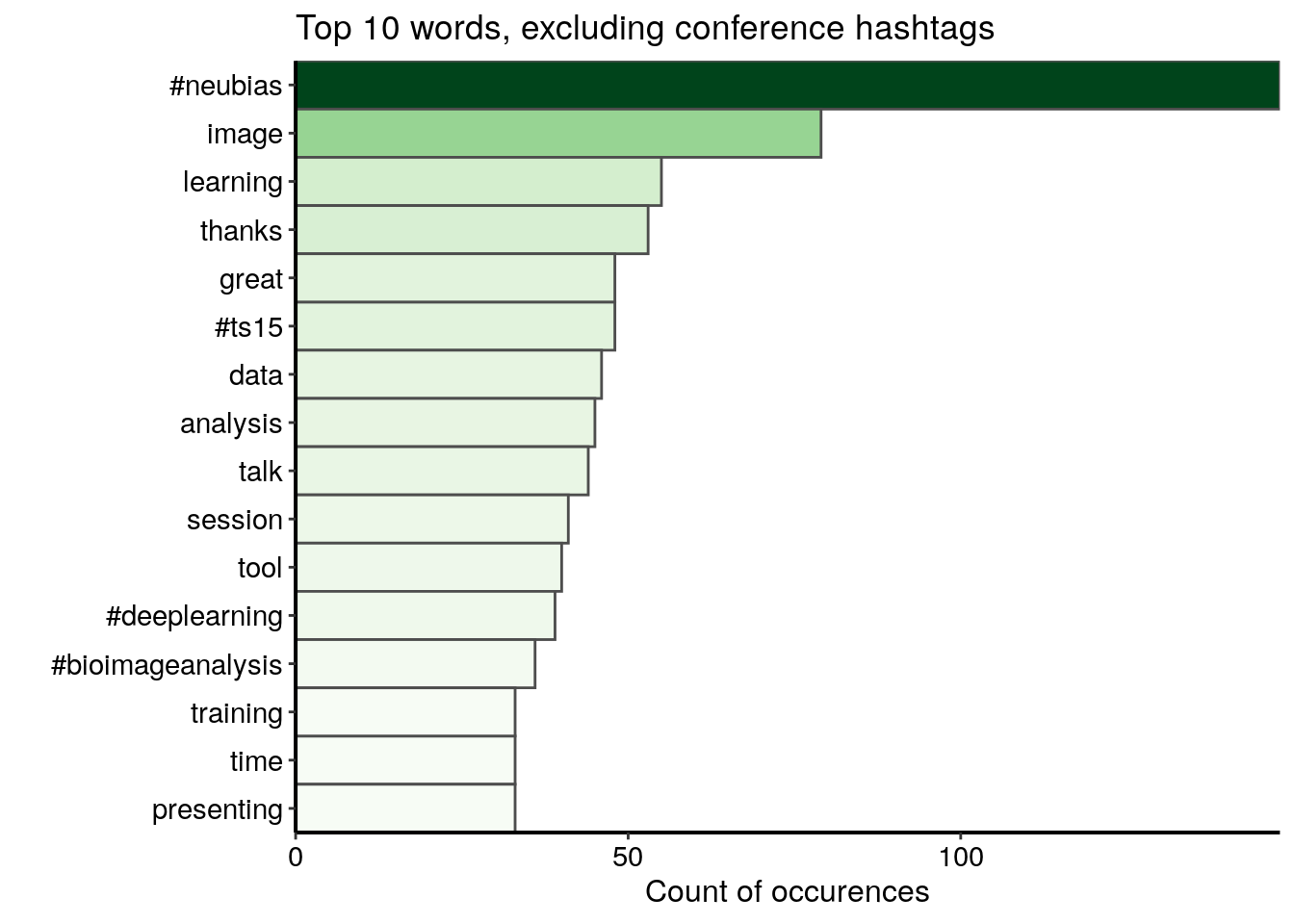
Je construis ensuite le nuage de mots. Cette fois je garde les hashtags de la conférence.
l <- nrow(d)
# Change to square root to reduce difference between sizes
d_sqrt <- d %>%
mutate(freq = sqrt(freq))
my_graph <- wordcloud2(
d_sqrt,
size = 0.5, # sqrt : 0.4
minSize = 0.1, # sqrt : 0.2
rotateRatio = 0.6,
gridSize = 5, # sqrt : 5
color = c(rev(tail(greenpal(50), 40)),
rep("grey", nrow(d_sqrt) - 40)) # green and grey
)
Conclusion
Cet article constitue la troisième et dernière partie de ma série “Analyser les données Twitter avec R”. Dans la première partie de cette série, j’ai expliqué comment j’ai collecté et agrégé les statuts Twitter contenant au moins un des hashtags de la conférence NEUBIAS. Dans la deuxième partie, j’ai exploré les profils des utilisateurs Twitter présents dans le jeu de données et leur relations.
Dans cette troisième et dernière partie, j’explore le contenu des tweets:
- j’ai identifié le hashtag de la conférence le plus populaire parmi les 5 hashtags suggérés par les organisateurs de la conférence
- j’ai extrait les hashtags associés aux hashtags de la conférence
- j’ai identifié les émojis les plus fréquemment utilisés et j’ai découvert que les émojis ne sont pas très présents dans ce jeu de données
- j’ai mis en évidence les mots les plus fréquemment utilisés à l’aide d’un nuage de mots
Remerciements
Je souhaite remercier le Dr. Sébastien Rochette pour son aide sur l’extraction des émojis.
Citation :
Merci de citer ce travail avec :
Louveaux M. (2020, Apr. 18). "Analyse de données Twitter avec R: Exploration du contenu des tweets". Retrieved from https://marionlouveaux.fr/fr/blog/2020-04-18_analysing-twitter-data-with-r-part3/.
@misc{Louve2020Analy,
author = {Louveaux M},
title = {Analyse de données Twitter avec R: Exploration du contenu des tweets},
url = {https://marionlouveaux.fr/fr/blog/2020-04-18_analysing-twitter-data-with-r-part3/},
year = {2020}
}

Partager ce post
Twitter
Google+
Facebook
LinkedIn
Email