
Candy phenotyping: Enseigner l'analyse d'image avec des bonbons
Enseigner l'analyse d'image et l'analyse de données avec des bonbons

Pour enseigner l’analyse d’image comme l’analyse de données, il faut utiliser un jeu de données comme exemple. Trouver un jeu de données numériques ou textuelles n’est le plus souvent pas un problème: de telles données peuvent être trouvées en ligne dans des bases de données publiques, ou bien être associées au logiciel d’analyse choisi, comme c’est le cas pour le logiciel de statistiques R, avec la librairie {datasets}. Certains de ces jeux de données sont même déjà correctement formattés et prêts à être utilisés pour enseigner l’exploration et la visualisation des données. Cependant, trouver un jeu de données d’images adéquat pour un enseignement peut se révéler plus compliqué, notamment si l’on souhaite combiner ce jeu de données d’images à un jeu de données textuelles et/ou numériques. Dans ce cas, il peut être nécessaire de créer son propre jeu de données. Comme la collecte et la mise en forme des données ont un impact direct sur leur analyse, de mon point de vue, ces étapes devraient faire partie intégrante des cours d’analyse de données (images, textuelles ou numériques).
Collecter des données ‘réelles’ pour de l’enseignement peut être compliqué. Cela prends du temps, mais cela peut aussi coûter de l’argent, et éventuellement poser des problèmes d’anonymat. Un de mes collègues chercheur à St Louis (États-Unis), Dan Chitwood, a trouvé un bon compromis: il a demandé à ses étudiants de collecter des images, ainsi que des données textuelles et numériques de bonbons. Les bonbons ont été photographiés par les étudiants. Leur valeurs nutritionnelles, ainsi que leur nom et leur type (‘chocolat’, ‘réglisse’…), ont été recopiés dans une base de données par les étudiants. Des informations supplémentaires concernant l’aspect des bonbons, ou leur ‘phénotype’ ont ensuite été déduites de l’analyse des photographies. J’ai eu l’occasion de donner un cours similaire, reprenant l’idée originale de Dan Chitwood, avec le professeur Alexis Maizel à l’université d’Heidelberg. J’expose dans cet article l’idée générale de ce cours, ses spécificités et sa valeur ajoutée.
Collecte d’images et de données numériques et textuelles
Les bonbons ont été achetés au supermarché. Le terme bonbons désigne ici les réglisses, les bonbons gélifiés, les caramels, les marshmallows, mais aussi les barres chocolatées, les truffes en chocolat… Ces bonbons sont de préférence emballés par type de bonbons plutôt que mixés, et l’emballage mentionne les valeurs nutritionnelles. La collecte des données se fait en plusieurs étapes. Tout d’abord, les paquets de bonbons reçoivent un identifiant unique (‘ID001’, ‘ID002’, ‘ID003’…). Puis tous les bonbons sont photographiés. Pour ce faire, nous avons préparé une table couverte d’une feuille de papier (blanche ou noire, pour contraster avec les bonbons), un pied photo pour positionner l’appareil photo au dessus de la table, une règle pour avoir l’échelle, et une étiquette avec l’identifiant des bonbons. Les étudiants devaient photographier 15 à 20 bonbons d’un même paquet à la fois. Enfin, les étudiants devaient recopier les valeurs nutritionnelles des bonbons et leur identifiant dans une feuille de calcul accessible en ligne (ici Google Spreadsheet).

Figure 1: Photos de bonbons prises par les étudiants de Dan Chitwood (gauche) et par nos étudiants (droite).
Comme dans tout travaux pratiques, rien ne s’est passé exactement comme prévu. Certains emballages contenaient un mélange de bonbons de couleur et/ou de forme différente, même si les valeurs nutritionelles indiquées étaient les mêmes. Sur les photographies, tous les bonbons n’étaient pas orientés de la même manière, certains dépassaient du cadre, d’autres étaient en contact les uns avec les autres, et la feuille blanche utilisée comme fond s’est rapidement retrouvée couverte de taches de chocolat. De plus, la base de données nutritionnelle n’était pas bien formattée. Les noms des bonbons et des fabricants étaient épelés de nombreuses facons (Nestlé, nestlé, nestle…), voire contenaient des erreurs de typographie. Nous n’avions pas donnés d’instructions concernant l’usage des accents, ce qui, avec les noms allemands des bonbons, a conduit à de nombreuses variations autour du même mot. Ce manque d’homogénéité s’est retrouvé accentué du fait de la saisie simultanée des données sur la feuille de calcul en ligne. Je pense que de tels ‘problèmes’ ne devraient pas être évités. Ils font partie des tracas de la collecte de données ‘réelle’. Il est nécessaire de procéder à l’analyse des données issues d’une telle collecte au moins une fois pour se rendre compte par soi-même à quel point les bonbons mixés, aggrégés ou mal positionnés peuvent affecter l’analyse d’image, et à quel point le manque d’homogénéité entre noms dans une base de données est préjudiciable à la poursuite de l’analyse.

Figure 2: Valeurs nutritionnelles sur un paquet de bonbons.
Analyse d’image avec Fiji
L’analyse d’image a été conduite avec le logiciel Fiji. Les étudiants étaient débutants en analyse d’image et sur Fiji. Nous avons donné un cours d’introduction sur ce qu’est une image (8 bits versus 16 bits, ce qu’est une LUT, comment ajuster la luminosité et le contraste…), ce qu’est un stack et un hyperstack, comment mesurer manuellement les propriétés des objets contenus dans une image (comment ajouter une échelle, ce qu’est un ROI, comment utiliser les outils de mesure…), et comment segmenter une image en utilisant les filtres et seuillages appropriés. L’objectif final était de segmenter les photographies des bonbons afin d’en extraire des mesures de l’aire des bonbons, ainsi que des descripteurs de forme (une valeur moyenne par identifiant de bonbon). Nous avons réparti le travail entre les étudiants, chacun recevant seulement quelques images à segmenter. Nous leur avons aussi demandé, en plus de l’image segmentée finale, d’expliquer leur méthode de segmentation, par exemple quels filtres ils avaient appliqué, s’ils avaient eu besoin de séparer les canaux RGB pour appliquer un seuil sur un canal uniquement etc.
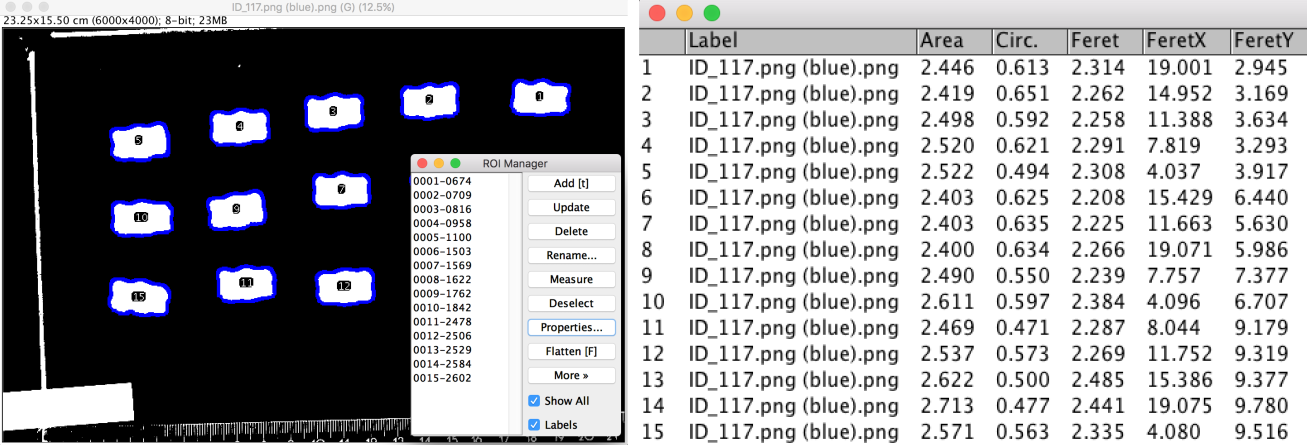
Figure 3: Image segmentée par seuillage dans Fiji (gauche). Les mesures sont extraites de l’image binarisée (droite).
Analyse de données avec R
L’analyse de données a été menée avec le logiciel de statistiques R. Les étudiants étaient débutants en analyse de données et en programmation sur R. Nous avons donné un cours d’introduction sur R à l’aide de la table des données nutritionelles. L’introduction était centrée sur comment charger la table de données, comment vérifier la qualité de la base de données et corriger les éventuelles erreurs, telles que des lignes dupliquées, des noms non homogènes…, et comment explorer graphiquement les données en utilisant la librairie {ggplot2}. Pour guider les étudiants, j’ai rédigé un document de cours au format Rmarkdown, avec l’aide d’un autre postdoctorant, Juan L. Mateo. J’ai utilisé un modèle inspiré d’un article de blog écrit par Sébastien Rochette. J’ai écrit deux versions: une version complète pour l’enseignant, avec toutes les réponses de code, et une à trous, pour les étudiants. Nous avons choisi de commencer par les bases, avec la définition d’un vecteur et d’une table de données. Nous n’avons pas parlé des librairies {dplyr} et {magrittr}, mais après avoir lu cet article de blog, j’aimerais bien essayer d’inclure ces librairies dans une future version de ce cours.
# load("nutrition_tidy.Rdata")
library(ggplot2)
g1 <- ggplot(nutrition_tidy) +
aes(x = calories_per_30g, y = total_carb_per_30g, colour = class) +
geom_point() +
theme(legend.position = "bottom")
g2 <- ggplot(nutrition_tidy) +
aes(x=class,y=calories_per_30g, fill = class) +
geom_boxplot() +
geom_jitter() +
guides(fill = FALSE)
gridExtra::grid.arrange(g1, g2, ncol = 2)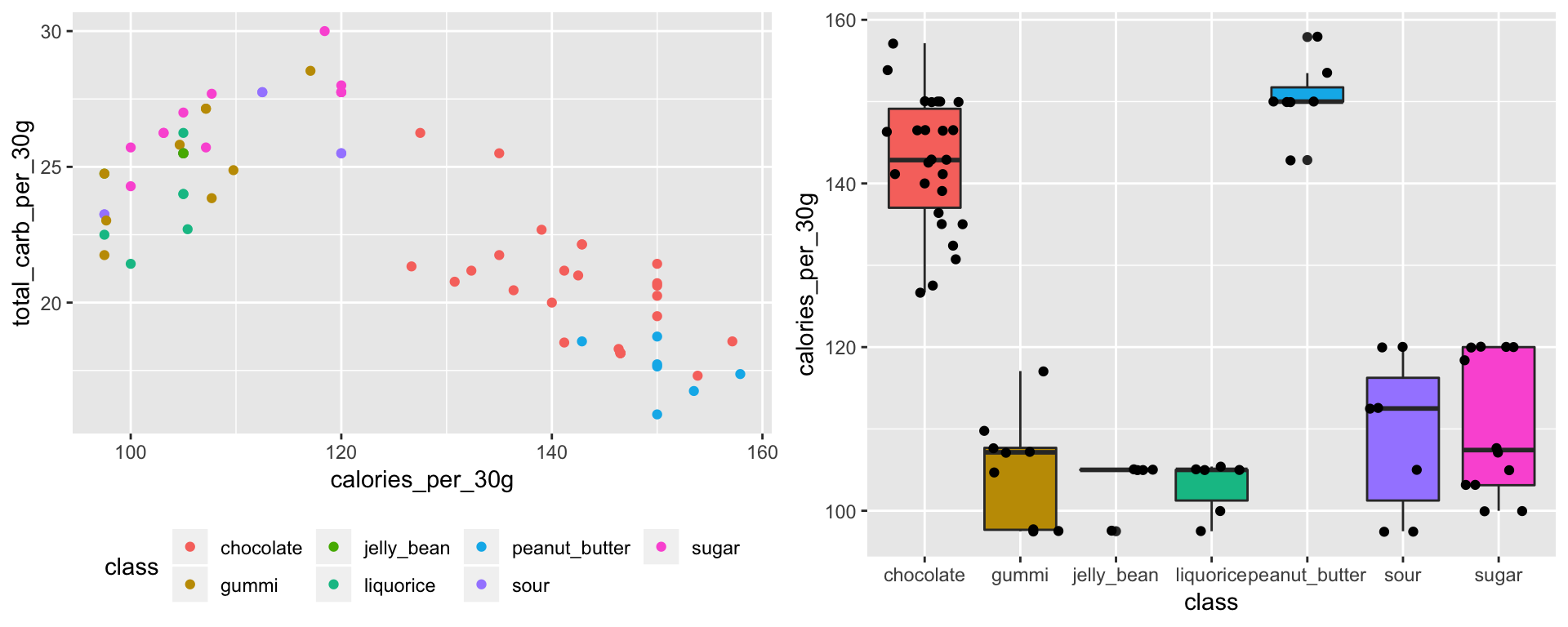
Pour aller plus loin - l’analyse multivariées et l’analyse morphométrique
Dans son cours, Dan Chitwood inclu également l’analyse de données multivariées. Nous n’avons pas été aussi loin car le planning était déjà serré, et nos étudiants débutants, à la fois sur Fiji et sur R. Si j’avais eu assez de temps, et/ou si les étudiants avaient déjà eu les bases en R et/ou Fiji, j’aurais inclu quelques heures au sujet de l’analyse en composantes principales, en utilisant par exemple la librairie R {FactoMineR}. Pour un cours plus avancé, j’aurais aussi inclu une introduction à l’analyse morphométrique. Dans la partie analyse d’image, nous avons seulement inclu quelques descripteurs de forme proposés par Fiji. Si j’avais eu plus de temps et des étudiants plus avancés, j’aurais introduit la librairie R {Momocs}. Cette librairie permet d’extraire la forme moyenne de chaque type de bonbon à partir des masques binaires obtenus par segmentation. Elle permet également de réaliser une analyse de Fourier pour obtenir une description succinte de la forme des bonbons, et de réaliser une analyse en composantes principales sur les harmoniques issues de l’analyse de Fourier.
Mes conseils
Je suggère de consacrer au moins 18h au cours complet (environ 9h pour l’acquisition des images et la partie sur Fiji, et 9h sur R). Ce cours est plutôt dense, surtout si les étudiants sont débutants. Je recommande donc très fortement de répartir les heures de cours sur plusieurs semaines, en espaçant chaque séance de 3h par 2 ou 3 jours. Comme il peut être assez risqué de réaliser le cours sur R directement sur les données fraîchement acquises par les étudiants qui pourraient n’être pas si bien formattées, je recommande de préparer le cours sur R sur le jeu de données de Dan Chitwood, qui contient quelques défauts bien choisis. La base de données nutritionelle créée durant le cours peut-être utilisée pour ré-appliquer les connaissance fraîchement acquises, en devoir à la maison ou en examen final.
Remerciements
J’aimerais remercier le professeur Alexis Maizel pour m’avoir donné l’opportunité de prendre part à la préparation et à la réalisation de ce cours, ainsi que Dan Chitwood pour son idée originale.
Citation :
Merci de citer ce travail avec :
Louveaux M. (2018, May. 20). "Candy phenotyping: Enseigner l'analyse d'image avec des bonbons". Retrieved from https://marionlouveaux.fr/fr/blog/candy-phenotyping/.
@misc{Louve2018Candy,
author = {Louveaux M},
title = {Candy phenotyping: Enseigner l'analyse d'image avec des bonbons},
url = {https://marionlouveaux.fr/fr/blog/candy-phenotyping/},
year = {2018}
}

Partager ce post
Twitter
Google+
Facebook
LinkedIn
Email