
Analyse de données Twitter avec R: Profils utilisateurs et relations entre utilisateurs
Partie 2: Exploration des profils utilisateurs et des relations entre utilisateurs
Dans cet article de blog, j’utilise le package R {rtweet} pour explorer les profils et relations des utilisateurs Twitter dont j’ai collecté les statuts lors d’une conférence scientifique. Il s’agit de la deuxième partie de ma série d’articles sur le thème “Analyse de données Twitter avec R”. Dans la première partie, j’ai montré comment j’ai comment j’ai collecté les statuts relatifs à une conférence scientifique.
Twitter est l’un des rares médias sociaux utilisés dans la communauté scientifique. Les utilisateurs ayant un profil scientifique sur Twitter communiquent sur la publication récente d’articles de recherche, les outils qu’ils utilisent, par exemple des logiciels ou des microscopes, les séminaires et conférences auxquels ils assistent ou leur vie de scientifique. Par exemple, sur mon compte Twitter personnel, je partage mes articles de blog, mes documents de recherche et mes diapositives, et je retweete (= je partage) ou je like (= j’aime) les sujets en lien avec la programmation avec R ou l’analyse d’images biologiques.
Twitter archive tous les tweets et offre une API pour effectuer des recherches sur ces données. Le package {rtweet} fournit une interface entre l’API de Twitter et R.
J’ai recueilli des données lors de la conférence 2020 NEUBIAS qui s’est tenue un peu plus tôt cette année à Bordeaux. NEUBIAS, pour “Network of EUropean BioImage AnalystS”, est un réseau scientifique créé en 2016 et soutenu jusqu’à cette année par les fonds européens COST. Les bioimage analysts extraient et visualisent des données provenant d’images biologiques (principalement des images de microscopie mais pas exclusivement) en utilisant des algorithmes et des logiciels d’analyse d’images développés par des laboratoires de recherche en analyse d’image pour répondre à des questions biologiques, soit pour leurs propres recherches en biologie, soit pour d’autres scientifiques. Je me considère comme une bioimage analyst, et je suis une membre active de NEUBIAS depuis 2017. J’ai notamment contribué à la création d’un réseau local de bioimage analysts lors de mon post-doctorat à Heidelberg de 2016 à 2019 et à la co-organisation de deux écoles thématiques NEUBIAS. J’ai également donné des cours et TD lors de trois écoles thématiques NEUBIAS. De plus, j’ai récemment co-créé un bot Twitter appelé Talk_BioImg, qui retweete le hashtag #BioimageAnalysis, afin d’encourager les gens de cette communauté à se connecter les uns aux autres sur Twitter (voir “Announcing the creation of a Twitter bot retweeting #BioimageAnalysis” and “Create a Twitter bot on a raspberry Pi 3 using R”, en anglais, pour plus d’informations).
Dans la première partie de cette série d’articles de blog intitulée “Analyse de données Twitter avec R: Collecte des statuts Twitter liés à une conférence scientifique”, j’ai expliqué comment j’ai récupéré les statuts Twitter contenant au moins un des hashtags de la conférence NEUBIAS.
Dans cette deuxième partie, je m’intéresse maintenant aux utilisateurs Twitter qui ont échangé ces statuts:
- le nombre total d’utilisateurs et les contributeurs principaux
- le réseau d’interations entre uttilisateurs
- la localisation géographique des utilisateurs, telle qu’indiquée sur leur profil
Packages
Pour obtenir des données sur les utilisateurs Twitter, j’utilise le package {rtweet}. Pour stocker et lire les données au format RDS, j’utilise {readr}. Pour manipuler et nettoyer les données, j’utilise {dplyr}, {forcats}, {purrr}, {stringr} et {tidyr}. Pour faire du géocodage de la localisation indiquée par les utilisateurs Twitter, j’utilise le package {opencage}. Pour construire des graphes de tweets et de retweets, j’utilise les packages {graphTweets} et {igraph}. Pour visualiser les données collectées, d’une manière générale, j’utilise {ggplot2} et {RColorBrewer}. Pour visualiser des réseaux j’utilise {visNetwork}, et pour faire des cartes, j’utilise {rnaturalearth} et {sf}.
library(dplyr)
library(forcats)
library(ggplot2)
library(graphTweets)
library(igraph)
library(opencage)
library(purrr)
library(RColorBrewer)
library(readr)
library(rnaturalearth)
library(rtweet)
library(sf)
library(stringr)
library(tidyr)
library(visNetwork)Graphiques: Thème et palette
Le code ci-dessous définit un thème et une palette de couleurs communs à toutes les graphiques. La fonction theme_set() de {ggplot2} définit le thème pour tous les graphiques.
# Define a personnal theme
custom_plot_theme <- function(...) {
theme_classic() %+replace%
theme(
panel.grid = element_blank(),
axis.line = element_line(size = .7, color = "black"),
axis.text = element_text(size = 11),
axis.title = element_text(size = 12),
legend.text = element_text(size = 11),
legend.title = element_text(size = 12),
legend.key.size = unit(0.4, "cm"),
strip.text.x = element_text(size = 12, colour = "black", angle = 0),
strip.text.y = element_text(size = 12, colour = "black", angle = 90)
)
}
## Set theme for all plots
theme_set(custom_plot_theme())
# Define a palette for graphs
greenpal <- colorRampPalette(brewer.pal(9, "Greens"))Données
Les données originales peuvent être téléchargées ici. Voir la partie 1 “Analyse de données Twitter avec R: Collecte des statuts Twitter liés à une conférence scientifique” pour plus d’informations sur comment j’ai collecté et aggrégé ces statuts Twitter.
Nombre total de contributeurs et contributeurs principaux
total_user_nb <- all_neubiasBdx_unique %>%
pull(screen_name) %>%
unique() %>%
length()
total_status_nb <- nrow(all_neubiasBdx_unique)
total_tweet_number <- all_neubiasBdx_unique %>%
filter(!is_retweet) %>%
pull(status_id) %>%
unique() %>%
length()Au total, 306 utilisateurs Twitter ont échangé des statuts Twitter contenant au moins un des hashtags de la conférence NEUBIAS. Comme je l’ai calculé dans la partie 1 “Analyse de données Twitter avec R: Collecte des statuts Twitter liés à une conférence scientifique”, 2629 statuts ont été échangés dont seulement 661 tweets, c’est à dire que seulement 25% des statuts étaient un contenu original. Vu la forte proportion de retweets, j’ai choisi de comparer la liste des 10 contributeurs principaux par nombre de tweets avec celle des contributeurs principaux par nombre de retweet.
Voici ci-dessous la liste des 10 contributeurs principaux par nombre de tweets:
top_contributors_tweet <- all_neubiasBdx_unique %>%
filter(!is_retweet) %>%
count(screen_name) %>%
arrange(desc(n)) %>%
top_n(10)
top_contributors_tweet %>%
knitr::kable()| screen_name | n |
|---|---|
| martinjones78 | 132 |
| pseudoobscura | 125 |
| MaKaefer | 49 |
| anna_medyukhina | 26 |
| MarionLouveaux | 25 |
| Nicolas26538817 | 24 |
| jmutterer | 22 |
| Zahady | 18 |
| basham_mark | 15 |
| IgnacioArganda | 14 |
Et voici maintenant la liste des 10 contributeurs principaux par nombre de retweets:
top_contributors_retweet <- all_neubiasBdx_unique %>%
filter(is_retweet) %>%
count(screen_name) %>%
arrange(desc(n)) %>%
top_n(10)
top_contributors_retweet %>%
knitr::kable()| screen_name | n |
|---|---|
| fab_cordelieres | 501 |
| Nicolas26538817 | 128 |
| sebastianmunck | 91 |
| NEUBIAS_COST | 87 |
| gomez_mariscal | 75 |
| VincentMaioli | 64 |
| martinjones78 | 61 |
| jmutterer | 55 |
| jytinevez | 43 |
| Olu_GH | 39 |
Seuls trois utilisateurs font partie des deux listes, ce qui suggère que les utilisateurs dans ce jeu de données sont soit des producteurs de contenu, soit des répétiteurs de contenu.
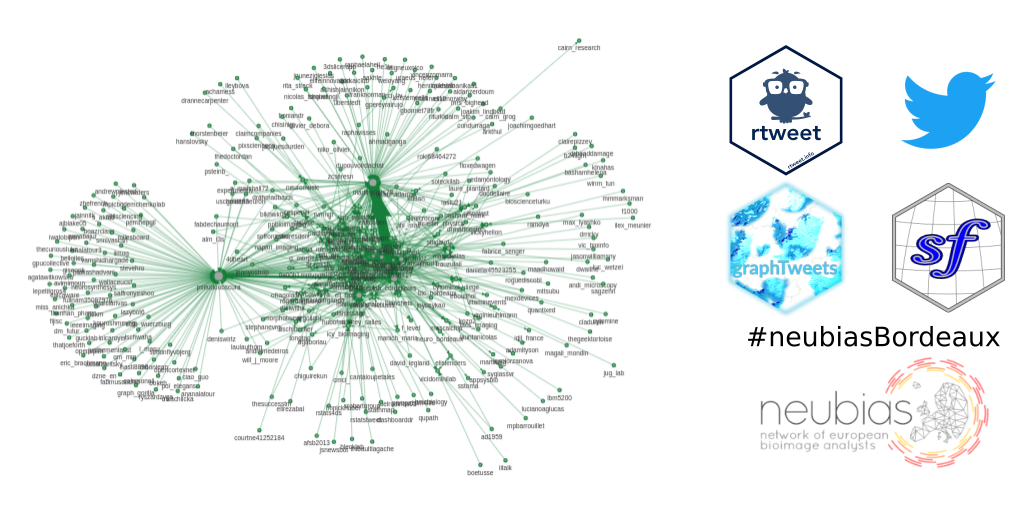
Graphe des utilisateurs
J’étais curieuse de visualiser le graphe des relations entre les utilisateurs, plus précisément, qui retweete qui. Pour construire ce graphe, j’ai utilisé le package {graphTweets} et j’ai converti le graphe en un objet igraph. Pour visualiser le graphe, j’ai utilisé le package {visNetwork} et la fonction visIgraph(). Chaque nœud correspond à un utilisateur de Twitter, et chaque arc correspond à un retweet. La taille du nœud correspond au nombre de fois que cette personne a été retweetée. La flèche pointe de l’utilisateur qui a fait le retweet vers l’utilisateur qui a été retweeté. La largeur de l’arc est proportionnelle au nombre de retweets.
Le graphique est interactif : utilisez la molette de la souris pour effectuer un zoom avant ou arrière, cliquez et faites glisser un point en arrière-plan pour déplacer l’ensemble du graphique, cliquez sur le centre d’un nœud pour mettre en évidence ce nœud et ses arcs, cliquez et faites glisser un point au centre d’un nœud pour déplacer ce nœud, et cliquez sur un arc pour le sélectionner.
net <- all_neubiasBdx_unique %>%
filter(is_retweet == TRUE) %>%
gt_edges(screen_name, retweet_screen_name) %>%
gt_nodes() %>%
gt_graph()
edges_col <- igraph::edge_attr(net, name = "n") %>%
cut(breaks = seq(0, 120, 20), labels = 1:6)
net <- set_edge_attr(graph = net, name = "width", value = 2^(as.numeric(edges_col)))
net <- set_vertex_attr(graph = net, name = "value", value = vertex_attr(net, name = "n"))
visIgraph(net) %>%
visLayout(randomSeed = 42, improvedLayout = TRUE) %>%
visEdges(
color = list(
color = greenpal(6)[5]
),
) %>%
visNodes(
color = list(
background = "#A3A3A3",
border = "##4D4D4D",
highlight = "#ff0000",
hover = "#00ff00"
),
font =
list(
size = 40
)
)J’ai été surprise de découvrir que si la plupart des utilisateurs ne retweetent un autre utilisateur qu’une ou deux fois, quelques utilisateurs retweetent beaucoup plus que cela, et ils retweetent beaucoup plus certains utilisateurs en particulier.
Obtenir la localisation approximative des utilisateurs de Twitter grâce au géocodage
Je voulais savoir de quels pays venaient les utilisateurs de Twitter présents dans mon jeu de données. Je m’attends à un biais pour les pays européens, car la conférence s’est tenue à Bordeaux, en France, et car NEUBIAS est, comme son nom l’indique, un réseau européen. En même temps, c’est aussi une conférence internationale, avec une réputation internationale, alors jetons un coup d’œil.
Twitter affiche le lieu que les utilisateurs acceptent d’indiquer. Il se peut que ce ne soit pas vrai, que ce ne soit pas exact, que ce soit mal orthographié, que ce ne soit pas un véritable lieu sur terre, ou que cela corresponde à plusieurs lieux sur terre. Pour ces raisons, je dois faire du géocodage, c’est-à-dire encoder la localisation donnée par l’utilisateur en coordonnées géographiques.
Voici par exemple la localisation de certains des utilisateurs de Twitter présents dans mon jeu de données:
users_location_example <- all_neubiasBdx_unique %>%
select(
screen_name,
location,
description
) %>%
distinct() %>%
head()
users_location_example %>%
knitr::kable()| screen_name | location | description |
|---|---|---|
| fabdechaumont | Playing with mice | |
| BlkHwk0ps | Just were I have to be. | Looping home 127.0.0.1 … always coming back to Python doctor, don´t know why… |
| AshishJainNikon | Eastern Canada | Advanced Imaging and Sales Specialist for Eastern Canada at Nikon Instruments |
| pseudoobscura | Berlin, Germany | Data Scientist | Bioimage Analyst @LeibnizFMP; Computer Vision; Data Analysis; Microscopy; Biology. |
| MascalchiP | Aquitaine, France | Formerly academic #microscopist, now sales & application specialist at DRVision #Aivia #AI #imageanalysis #cloud #machinelearning #deeplearning #VR #microscopy |
| Laura_nicolass | Madrid, Comunidad de Madrid | PhD student Uc3m. Studying multimodal image registration and part of ERA4Tb tuberculosis project. |
Pour faire du géocodage, j’utilise le package {opencage}, qui est une interface avec l’API OpenCage. Pour utiliser le package {opencage}, il faut créer un compte sur l’API Open Cage, ce qui permet d’obtenir un token. Le token doit être stocké dans le fichier .Renviron. Pour ce faire, ouvrez le fichier avec la commande ci-dessous, et ajoutez la ligne suivante OPENCAGE_KEY="your_token_here" avec votre propre token.
usethis::edit_r_environ()Comme le montre la figure ci-dessous, je passe par trois étapes : (1) obtenir la position de l’utilisateur à partir de l’API Twitter, (2) encoder ces localisations lisibles par un humain en coordonnées géographiques avec l’API OpenCage, et (3) vérifier et nettoyer le résultat pour ne garder qu’un seul ensemble de coordonnées géographiques par utilisateur.

Je récupère d’abord toutes les informations sur les utilisateurs de Twitter présents dans le jeu de données en utilisant la fonction lookup_users() de {rtweet}.
user_info <- lookup_users(unique(all_neubiasBdx_unique$user_id))
write_rds(user_info, path = "data_out_neubias/user_info.rds")Puis, j’extrais les informations de localisation du profil de chaque utilisateur et j’utilise la fonction opencage_forward() du package {opencage} pour encoder cette localisation en latitude et longitude. Et je stocke ces informations dans un fichier .rds, car le nombre d’appels à l’API OpenCage est limité par jour, et ce n’est pas une bonne pratique de surcharger inutilement l’API avec des requêtes répétitives.
location_forward <- user_info %>%
filter(location != "") %>%
distinct(location) %>%
pull(location) %>%
map(function(x) opencage_forward(placename = x, no_record = TRUE)) # does not save the exact query
readr::write_rds(location_forward, path = "data_out_neubias/2020-03-29_location_forward.rds")Pour chaque utilisateur de Twitter, j’ai maintenant un ou plusieurs lieux géographiques supposés. Le géocodage n’est pas précis à 100% : il fournit souvent plusieurs ensembles de coordonnées géographiques très proches les unes des autres et correspondant au même lieu, mais il peut aussi fournir des ensembles qui correspondent à des lieux très différents, appartenant même parfois à des pays différents.
J’aimerais ne garder qu’une seule localisation par utilisateur pour faire une carte. Ma stratégie consiste à vérifier la cohérence des résultats en utilisant la variable components.country fournie par la fonction opencage_forward(), plutôt que la latitude et la longitude.
Pour cela, j’ai écrit la fonction country_check(). Cette fonction extrait la variable components.country, et vérifie si elle est unique. Si elle est unique, c’est-à-dire s’il n’y a qu’un seul ensemble de coordonnées géographiques ou s’il y en a plusieurs mais qu’elles sont toutes situées dans le même pays, la fonction conserve le premier ensemble de coordonnées. Dans le cas contraire, elle renvoie “NA”.
#' This function checks if one or several countries have been found for a given location by opencage_forward
#'
#' @param coded_elt result of forward geocoding request
#'
#' @return the first result if country is unique, NA otherwise
#'
#' @importFrom purrr pluck
#' @export
#'
#' @examples
country_check <- function(coded_elt) {
if (pluck(coded_elt, "total_results") == 0) { # no results
pluck(coded_elt, "results")
} else { # one or several results
if (pluck(coded_elt, "total_results") == 1) { # one result
pluck(coded_elt, "results")
} else { # several results
if (length(unique(pluck(coded_elt, "results", "components.country"))) == 1) { # one country
pluck(coded_elt, "results")[1, ]
} else { # several countries
pluck(coded_elt, "results")[pluck(coded_elt, "total_results") + 1, ]
}
}
}
}J’applique maintenant cette fonction sur les localisations que j’ai stockées.
location_forward_checked <- location_forward %>%
map_df(country_check)Je peux maintenant joindre l’information géographique aux données des utilisateurs. La requête sauvegardée par opencage_forward() ne correspond pas exactement à la chaîne de caractères stockée dans user_info. Pour faire une jonction propre entre les informations des utilisateurs et les coordonnées géographiques, je commence par nettoyer les colonnes location et query en utilisant les fonctions suivantes du paquet {stringr} : str_trim(), qui supprime les espaces blancs au début et à la fin d’une chaîne de caractères, et str_to_lower(), qui convertit une chaîne de caractères en minuscules.
user_info_clean <- user_info %>%
mutate(location_clean = str_trim(location) %>% str_to_lower())
location_forward_checked_clean <- location_forward_checked %>%
mutate(query_clean = str_trim(query) %>% str_to_lower()) %>%
group_by(query_clean) %>%
summarise_all(first)
user_info_with_loc <- left_join(user_info_clean, location_forward_checked_clean, by = c("location_clean" = "query_clean"))Afficher l’origine des utilisateurs sur une carte du monde
Dans la figure ci-dessous, je récapitule les deux étapes nécessaires pour afficher la localisation des utilisateurs sur la carte du monde. J’ai déjà une information sur le pays provenant des résultats de la requête vers l’API OpenCage. Cependant, je ne suis pas sûre que les noms des pays dans OpenCage correspondent aux noms que j’ai dans la carte du monde de {rnaturalearth}. Par exemple, je pourrais avoir “USA” dans l’un et “United States of America” dans l’autre. La stratégie consiste ici à (1) joindre l’ensemble des coordonnées géographiques sur la carte du monde en utilisant la fonction st_join() de {sf}, et ensuite, (2) utiliser les pays de la carte du monde sur lesquels sont situés ces points.
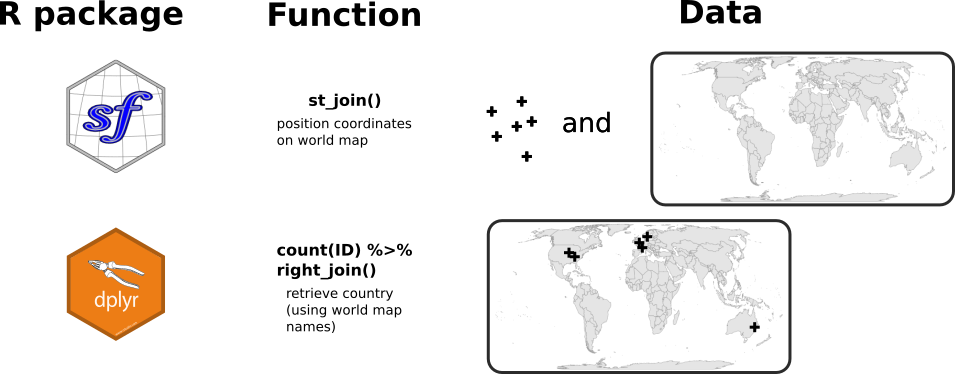
J’importe tout d’abord un fond de carte du monde provenant du package {rnaturalearth}.
map_world <- ne_countries(type = "countries", returnclass = "sf", scale = "medium") %>%
lwgeom::st_make_valid() %>%
mutate(ID = 1:n()) %>%
# Choose a projection correct for the World (Eckert IV)
st_transform(map_world, crs = "+proj=eck4 +lon_0=0 +x_0=0 +y_0=0 +datum=WGS84 +units=m +no_defs")
map_world_centroid <- map_world %>%
st_centroid(of_largest_polygon = TRUE)Puis, je transforme les localisations des utilisateurs en objet de type sf.
location_as_sf <- user_info_with_loc %>%
filter(!is.na(geometry.lat) & !is.na(geometry.lng)) %>%
select(geometry.lat, geometry.lng) %>%
st_as_sf(coords = c("geometry.lng", "geometry.lat"), crs = 4326) %>%
st_transform(map_world, crs = "+proj=eck4 +lon_0=0 +x_0=0 +y_0=0 +datum=WGS84 +units=m +no_defs")Je joins les localisations des utilisateurs avec les pays en utilisant la fonction st_join() (jointure spatiale) et je compte le nombre d’utilisateurs par pays.
nb_users_from_map <- location_as_sf %>%
st_join(map_world) %>%
st_drop_geometry() %>%
count(ID) %>%
right_join(map_world_centroid, by = "ID") %>%
filter(!is.na(n))J’affiche la carte du monde et le nombre d’utilisateurs par pays sous forme de points positionnés sur le centroide des pays. La taille du point est proportionnelle au nombre d’utilisateurs et la couleur change également en fonction du nombre d’utilisateurs pour aider à distinguer les petits points des plus grands.
ggplot() +
geom_sf(data = map_world, fill = "grey90", color = "grey60", size = 0.2) +
geom_sf(
data = nb_users_from_map,
aes(geometry = geometry, size = n, color = n), show.legend = "point"
) +
scale_color_viridis_c() +
scale_size_continuous(range = c(1, 10)) +
labs(color = "Number\nof Twitter users") +
custom_plot_theme() +
coord_sf()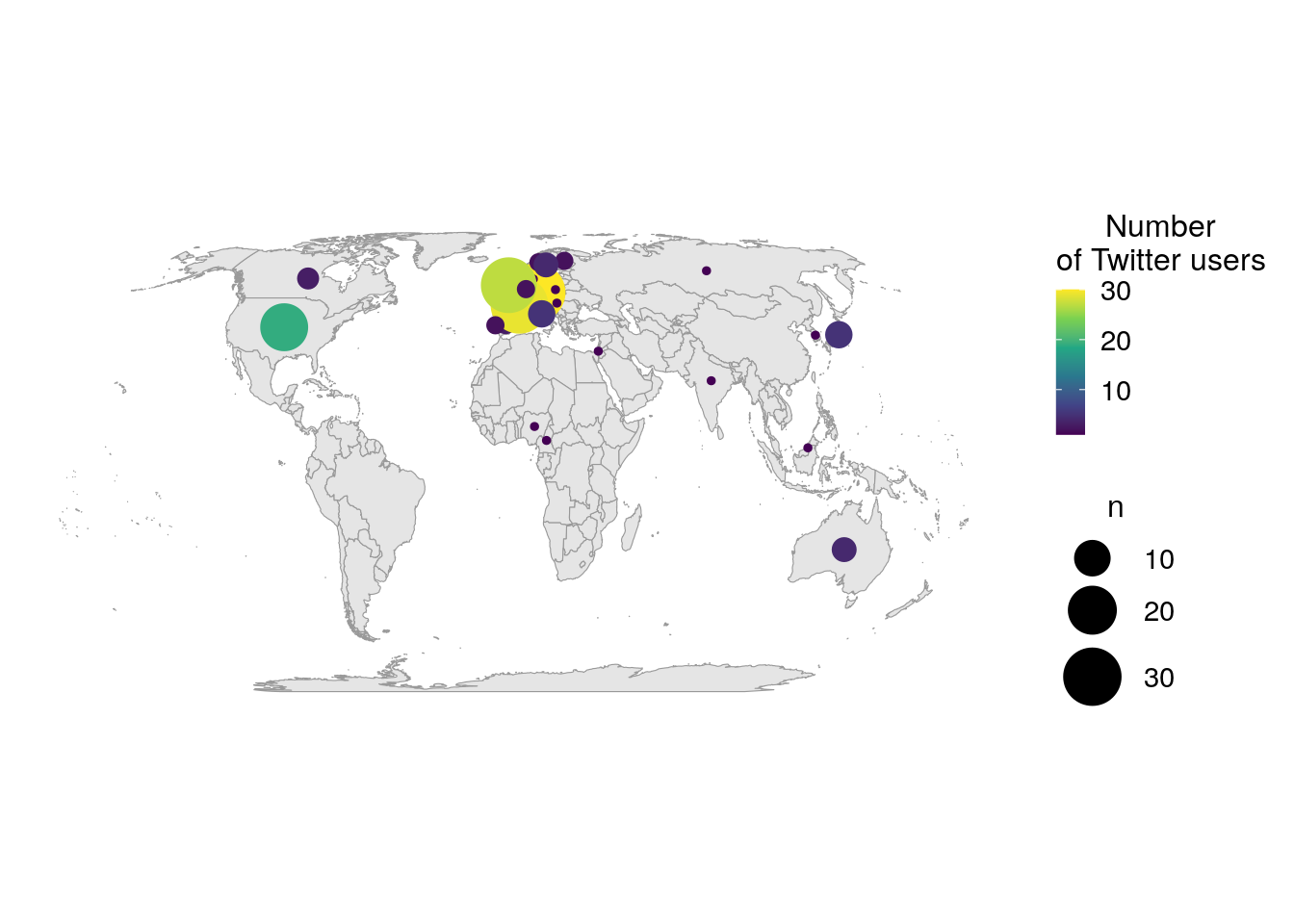
Comme il y a beaucoup d’utilisateurs en Europe, je zoome sur cette partie du monde.
europe_cropped <- st_crop(map_world, xmin = -2000000, xmax = 8374612 , ymin = 4187306 , ymax = 8374612)
ggplot() +
geom_sf(data = europe_cropped, fill = "grey90", color = "grey60", size = 0.2) +
geom_sf(
data = filter(nb_users_from_map, continent == "Europe"),
aes(geometry = geometry, size = n, color = n), show.legend = "point"
) +
scale_color_viridis_c() +
scale_size_continuous(range = c(1, 10)) +
labs(color = "Number\nof Twitter users") +
custom_plot_theme() +
coord_sf(expand = FALSE)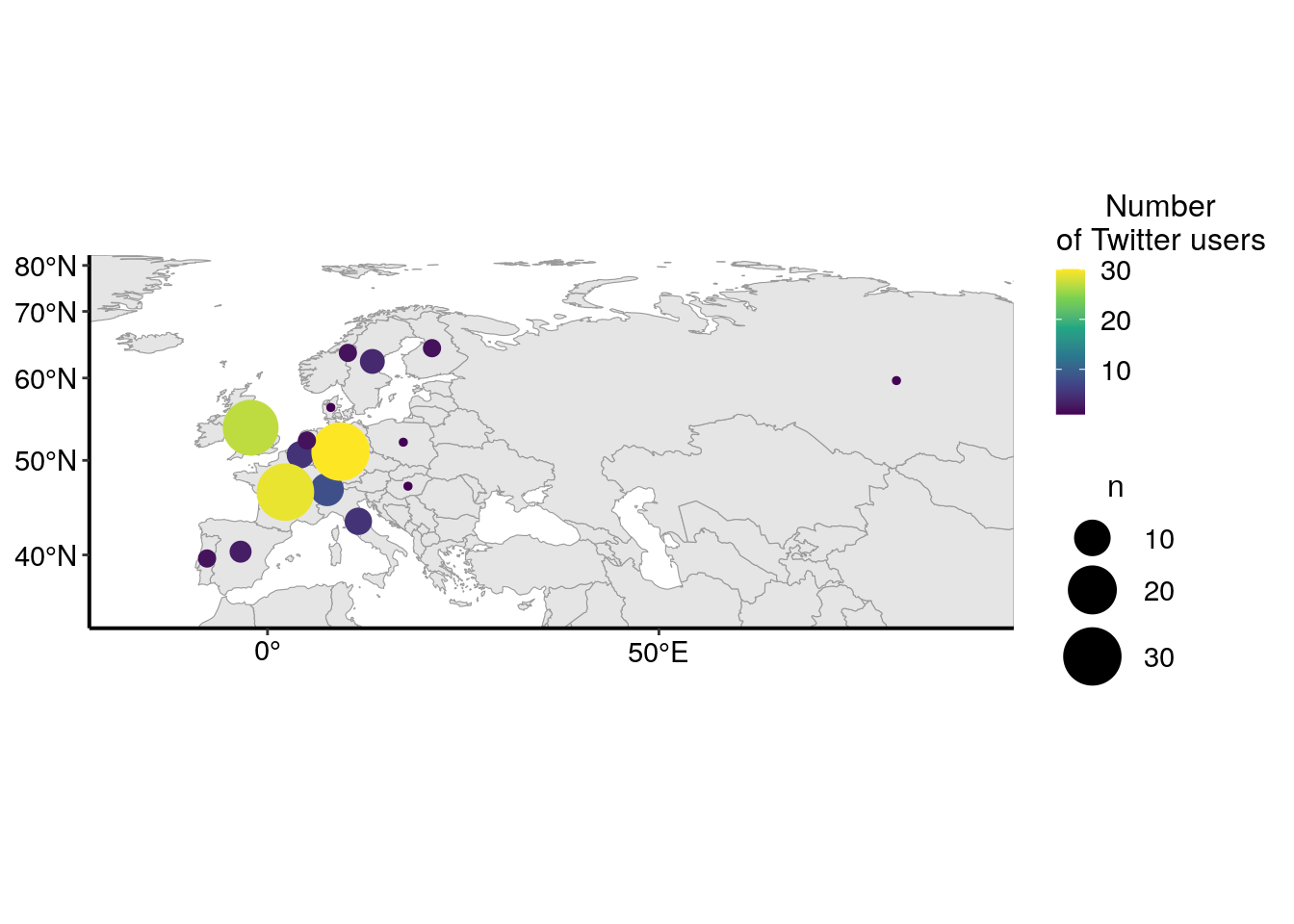
Comme expliqué plus haut, je m’attendais à un nombre assez élevé d’utilisateurs de Twitter en Europe. Il est intéressant de noter qu’il y a aussi beaucoup d’utilisateurs des États-Unis, mais aussi d’autres pays, comme le Canada, l’Australie ou le Japon. Le graphique ci-dessous représente le nombre d’utilisateurs de Twitter pour les dix pays les plus représentés dans mon jeu de données. Je peux raisonnablement supposer que tous les utilisateurs de Twitter qui ont utilisé les hastags de la conférence n’étaient pas présents à la conférence. Ainsi, le graphique ci-dessous représente plus l’écho international que cette conférence a eu sur Twitter que l’origine des participants à la conférence.
nb_users_from_map %>%
top_n(10, n) %>%
ggplot(aes(x = reorder(name_long, n), y = n)) +
geom_col(fill = greenpal(2)[2]) +
coord_flip() +
labs(
x = NULL,
y = "Number of Twitter users"
) +
custom_plot_theme() +
scale_y_continuous(expand = c(0, 0))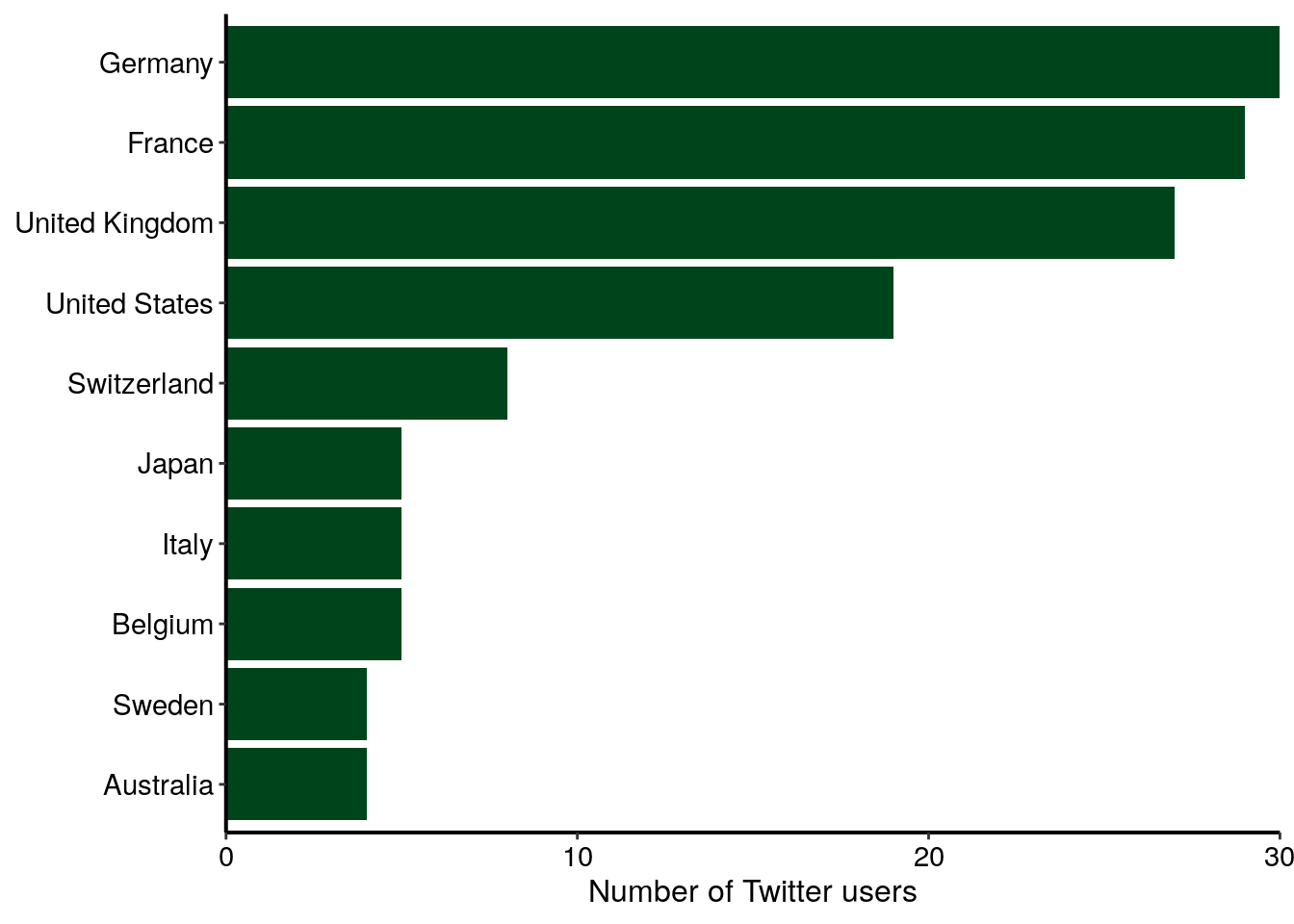
Conclusion
Dans la première partie de cette série “Analyser les données Twitter avec R : collecter les statuts Twitter liés à une conférence scientifique”, j’ai expliqué comment j’ai collecté et agrégé les statuts Twitter contenant au moins un des hashtags de la conférence NEUBIAS.
Ici, dans cette deuxième partie, j’ai examiné le profil des utilisateurs de Twitter présents dans ce jeu de donnée. Premièrement, j’ai compté le nombre total d’utilisateurs qui avaient posté des statuts Twitter contenant au moins un des hashtags de la conférence NEUBIAS, et j’ai classé les dix principaux contributeurs pour le nombre de tweets et de retweets. Deuxièment, j’ai dessiné un réseau d’interaction entre ces utilisateurs, en cherchant qui retweettait qui. Troisièmement, j’ai créé une carte localisant les utilisateurs, en utilisant la localisation inscrite sur leur profil Twitter.
Dans la troisième partie de cette série, j’explorerai le contenu des tweets.
Remerciements
Je souhaite remercier le Dr. Sébastien Rochette pour son aide sur {sf}.
Ressources
Je recommande vivement de lire la vignette {rtweet}, la vignette {graphTweets}, la vignette {visNetwork} et la vignette {opencage}. Je recommande aussi de lire cet article de blog sur comment zoomer sur des cartes avec {sf} et {ggplot2}.
Citation :
Merci de citer ce travail avec :
Louveaux M. (2020, Mar. 29). "Analyse de données Twitter avec R: Profils utilisateurs et relations entre utilisateurs". Retrieved from https://marionlouveaux.fr/fr/blog/twitter-analysis-part2/.
@misc{Louve2020Analy,
author = {Louveaux M},
title = {Analyse de données Twitter avec R: Profils utilisateurs et relations entre utilisateurs},
url = {https://marionlouveaux.fr/fr/blog/twitter-analysis-part2/},
year = {2020}
}


Partager ce post
Twitter
Google+
Facebook
LinkedIn
Email